[Face Recognition] 1. MTCNN 논문 리뷰
in Paper-Review
![[Face Recognition] 1. MTCNN 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/Paper-Review/image/MTCNN/img0.png?raw=true)
MTCNN: Joint Face Detection and Alignment using Multi task Cascaded Convolutional Networks
모델 구조

MTCNN은 3개의 neural network(P-Net, R-Net, O-Net)로 이루어져 있다. 이때 각 net에서 face classification과 bbox regression, face landmark localization 과정을 진행하면서 동시에 학습시키는 방식(joint learning)을 사용한다. joint learning을 통해 기존의 다른 방법에 비해 정확도가 높고 속도가 빠르며 그렇기 때문에 지금까지도 많이 쓰이고 있는 논문이다.
MTCNN의 구조를 단계별로 살펴보면 아래와 같이 총 4단계로 이루어진다.
0단계. Image Pyramid
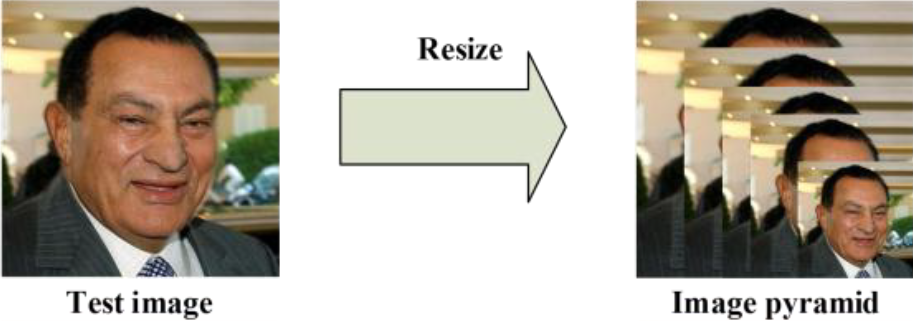
본격적으로 detection이 이루어지기 전에 위와같이 input되는 이미지를 각기 다른 scale로 resize하여 image pyramid를 만든다. 이는 앞서 살펴보았던 SSD에서와 같이 다양한 scale의 이미지로 다양한 사이즈의 얼굴을 더 잘 detection하기 위해서 라고 볼 수 있다.
1단계. P-Net(Proposal Network)

첫번째로 P-Net은 이미지에서 얼굴을 찾아내는데 중점을 둔 network이다. P-Net은 이 논문에서 ‘We exploit a fully convolutional network[?]’이라고 말했듯이 fully connected layer가 없고 conv layer로 이루어진 것이 특징이다.
이는 [“Multi-view face detection using deep convolutional neural networks,” in ACM on International Conference on Multimedia Retrieval, 2015, pp. 643-650.]에서 bbox regression vector와 후보 영역을 구하는 방법과 유사하다.
P-Net을 통해 수 많은 bbox regression vector와 후보 영역을 얻게되는데 이들을 NMS(non-maximum suppression)알고리즘으로 높은 정확도의 후보 영역만 남도록 추려낸다. 그리고 남은 후보영역의 face classification, bbox regression, face landmark localization 값을 다음 단계로 보낸다.
2단계. R-Net(Refine Network)

두번째로 R-Net은 P-Net에서 찾아낸 후보 영역을 추려내는데 중점을 둔 network이다. R-Net의 구조는 P-Net의 구조와 유사하지만 fully connected layer가 끝에 추가됬다는 점이 특징이다.
R-Net에서도 bbox regression vector와 후보 영역을 얻어내고, 이들을 NMS(non-maximum suppression)알고리즘으로 높은 정확도의 후보 영역만 남도록 추려낸다. 이때 fully connected layer가 있기때문에 조금더 정확한 값을 추려낼 수 있다고 추측할 수 있다. 마찬가지로 남아있는 후보영역의 face classification, bbox regression, face landmark localization 값을 다음 단계로 보낸다.
3단계. O-Net(Output Network)
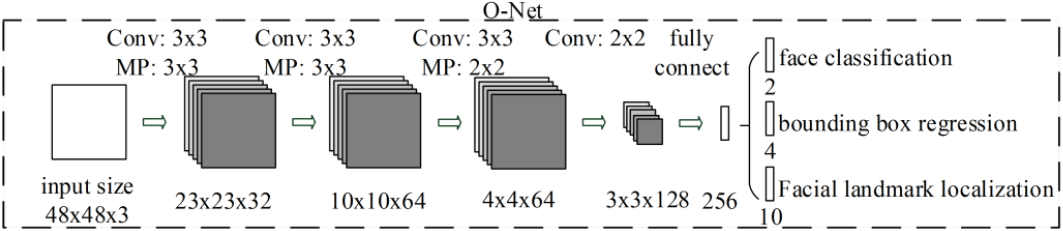
세번째로 O-Net은 이전 단계에서 찾아낸 후보 영역에서 face landmark를 찾아내는데 중점을 둔 network이다.
이를 통해 최종적인 face classification, bbox regression, face landmark localization값을 얻게 된다.
이때 각 단계에서 얻어내는 값들을 자세히 살펴보면 아래와 같다.
- face classification (2개)
ydet = GT에서 얼굴이 있는지 여부(있을때 1, 없을때 0)
p = 얼굴이 있을 확률- bbox regression (4개)
예측한 bbox의 왼쪽상단 x,y좌표
예측한 bbox의 너비와 높이- face landmark localization (10개)
왼쪽 눈의 x,y 좌표
오른쪽 눈의 x,y 좌표
코의 x,y 좌표
입의 왼쪽 끝 부분의 x,y 좌표
입의 오른쪽 끝 부분의 x,y 좌표
학습 데이터
학습에는 아래와 같은 4가지 종류의 데이터가 필요하다.
- Negatives: Regions that the Intersec-tion-over-Union (IoU) ratio less than 0.3 to any ground-truth faces
- Positives: IoU above 0.65 to a ground truth face
- Part faces: IoU between 0.4 and 0.65 to a ground truth face
- Landmark faces: faces labeled 5 landmarks’ positions
이때 각 단계별로 살펴보면
- P-Net
먼저 ‘WIDER FACE’를 랜덤 크롭한 패치들을 positives, negatives and part face로 나눴고, ‘CelebA’에서 얼굴을 크롭하여 landmark faces를 구하여 학습에 사용하였다.
- R-Net
앞서 P-Net에서 얻은 결과를 사용하였다.
- O-Net
앞서 P-Net과 R-Net에서 얻은 결과를 모두 사용하였다.
Loss Function과 joint train의 효과
- Face Classification loss
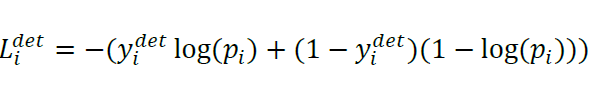
ydet(GT에서 얼굴이 있는지 여부(있을때 1, 없을때 0)) 와 p(얼굴이 있을 확률)의 cross entropy 값을 통해 Face Classification loss를 구한다.
- Bounding box Regression loss

bbox의 왼쪽상단 x,y좌표, 높이, 너비로 이루어진 4개의 값과 GT의 값의 차이를 Euclidean norm으로 구한다.
- Facial landmark Localization loss
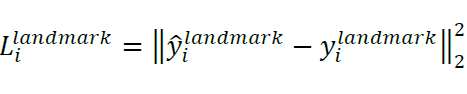
얼굴의 다섯개의 포인트(두 눈, 코, 입의 양쪽 끝 부분)의 x,y 좌표값과 GT의 값의 차이를 Euclidean norm으로 구한다.
- Multi-source training loss

각 단계에서 구한 loss값을 각 단계의 특징에 맞게 학습시키기위해 위의 식을 사용하였다. 각 요소들의 의미를 살펴보면아래와 같다.
αj는 각 단계마다 각 loss의 가중치를 다르게 주기위해 사용되었다. 이 논문에서는 P-Net과 R-Net에 (αdet = 1, αbox = 0.5, αlandmark = 0.5)를 주어 detection에 중점을 두었다.
O-Net에서는 (αdet = 1, αbox = 0.5, αlandmark = 1)를 주어 facial landmark localization에 중점을 두었다.
βj는 특정 샘플이 선택되었는지 여부를 (0,1)로 나타낸다.
Lj은 위에서 구한 각 목적별 loss값이다.
- joint train의 효과

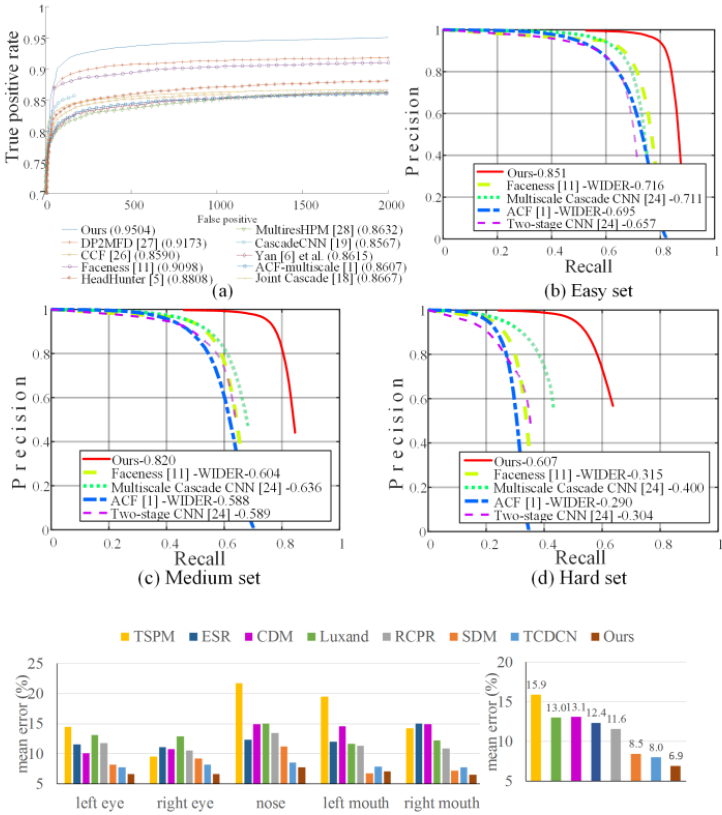
MTCNN은 위와 같은 loss값으로 joint training을 진행하는데, 그래프에서 보면 알 수 있듯이 joint training을 통해 큰 폭으로 성능이 높아진 것을 알 수 있다.
기존 모델과의 성능 비교
- 기존 논문(“A convolutional neural network cascade for face detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 5325-5334.)과의 단계별 성능비교

- 여러 데이터셋에서의 성능비교