[LightWeight DL] 1. SQUEEZENET 논문 리뷰
in Paper-Review
![[LightWeight DL] 1. SQUEEZENET 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/Paper-Review/image/SQUEEZENET/img0.png?raw=true)
SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
모델 특징

기존의 모델들은 고성능의 System Resource내에서 높은 정확도를 목표로 설계되어 있었다. 특히 이 논문의 대조군인 AlexNet은 classification에서 높은 정확도를 보여줬지만 모델이 너무 무거워 낮은 성능의 System Resource에서는 사용하기 어려웠다.
하지만 SQUEEZENET은 그림과 같이 오렌지에서 즙을 짜는것(SQUEEZE)처럼 기존 모델의 성능을 유지하면서 용량과 파라미터 수는 줄이도록 설계하였다. 이 논문에서 개인적으로 제일 마음에 드는 부분은 제목이다.
ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
기존의 모델(AlexNet)과 같은 정확도이면서 파라미터 수를 50배나 줄였고 용량을 0.5MB이하로 줄였다고 당당히 말하는 것이 너무 멋있는것 같다. ㅎㅎ
먼저 이 논문에서 제안한 주요 아이디어를 살펴 보면 아래와 같다.
Fire Module

이 논문에서 제안한 Fire Module은 그림에서와 같이 Squeeze layer와 Expand layer로 이루어져 있다.
- Squeeze layer
Squeeze layer는 1x1 Conv로 이루어져 있다. 이는 각 채널간의 정보를 linear combination하는 Pointwise Conv의 역할을 진행한다. 이 부분에서 모델의 용량과 파라미터를 수를 줄여주는 과정이 일어난다.
- Expand layer
Expand layer는 1x1 Conv와 3x3 Conv로 이루어져 있다. 모델을 가볍게 해줄 수 있지만 feature extraction을 잘 하지 못하는 1x1 Conv와 feature extraction을 잘하지만 모델을 무겁게 하는 3x3 Conv이 상호 보완적관계로 같이 쓰이는 것이다. 이때 파라미터 값을 조절하여 1x1 Conv와 3x3 Conv의 수를 조절할 수 있다.
Vanilla vs Simple bypass vs Complex bypass
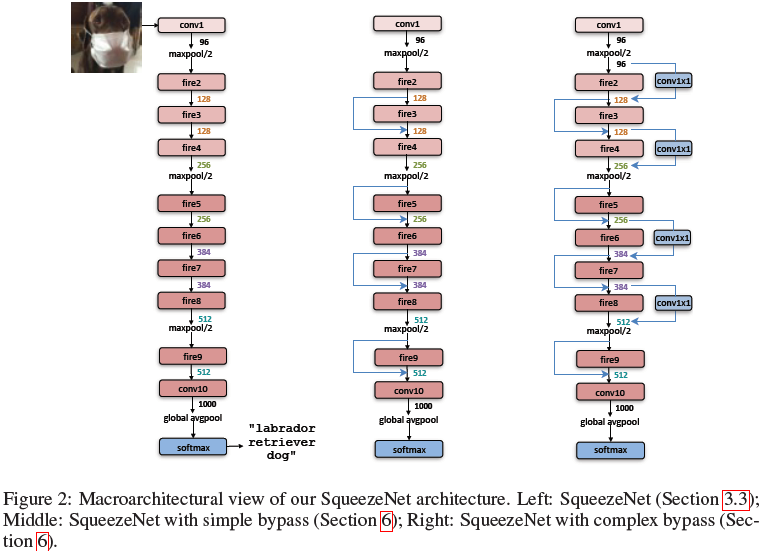
논문에서는 앞서 제안한 Fire Module에 bypass라는 아이디어를 활용하여 위와같이 세가지 형태의 모델(Vanilla, Simple bypass, Complex bypass)를 만들었고, 세 모델의 성능을 비교하는 실험을 진행하였다.
여기서 bypass는 ResNet의 skip connection과 같은 개념으로 이전 layer(ex. fire6)의 output값을 bypass로 가져와 직전 layer(ex. fire7)의 output값과 elementwise addition하여 다음 layer(ex. fire8)에 input하는 것이다. 실험의 결과는 아래와 같다.

기본적인 SqueezeNet(Vanilla)에 비해 Simple bypass를 추가한 모델이 가장 성능이 좋은 것으로 나타났다.
Squeeze ratio(SR) & Percentage of 3x3 filters in expand layers
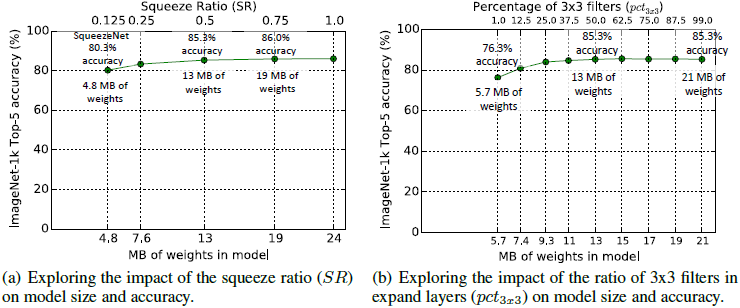
- Squeeze ratio(SR)
왼쪽의 그래프 (a)는 Squeeze ratio(SR)에 따른 모델의 용량과 정확도가 나타나있는 그래프이다. Squeeze ratio(SR)는 Squeeze layer에서 Expand layer로 들어가는 input의 channel 수를 나타내는 값이다. SR값이 클 수록 모델의 용량이 크고 정확도가 높아지는 경향이 있고, 0.25를 기준으로 성능이 급격하게 떨어지는 경향이 있다.
- Percentage of 3x3 filters in expand layers
오른쪽의 그래프 (b)는 expand layers에서의 3x3 Conv의 비율을 의미한다. 3x3 Conv의 비율이 높을 수록 모델의 용량이 크고 정확도가 높아지는 경향이 있고, 0.25를 기준으로 성능이 급격하게 떨어지는 경향이 있다.
Result
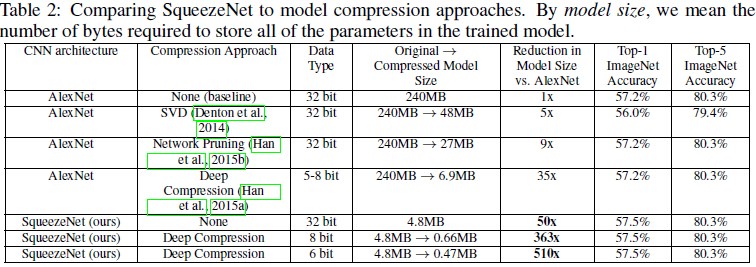
제목에서 언급한바와 같이 SQUEEZENET을 대조군인 AlexNet과 비교해 보면, 사이즈가 기본 AlexNet과 무려 50배의 차이가 나는 것을 알 수 있다. 이때 심지어 SQUEEZENET이 정확도 또한 높은것을 알 수 있다.
그 다음 두 모델에 Deep Compression(Han et al., 2015a)을 적용한 결과를 보면 SQUEEZENET은 0.47MB까지 사이즈가 줄어들고, 기본 AlexNet과 무려 510배의 차이가 나는 것을 알 수 있다. 이때도 심지어 SQUEEZENET의 정확도가 더 높은것을 알 수 있다.