[Object Detection] 5. SSD 논문 리뷰
in Paper-Review
![[Object Detection] 5. SSD 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/Paper-Review/image/SSD/img0.png?raw=true)
SSD: Single Shot MultiBox Detector (SSD)
모델 구조

SSD의 구조는 위의 그림과 같다. 먼저 pretrained된 VGG를 통해 feature를 추출한다. 그 다음 추출된 feature map을 각기 다른 size의 convolution layer를 통과시키며 각 layer에서 detection을 수행한디.
각 layer에서 얻은 결과는 다음 layer로 보냄과 동시에 마지막으로 보내 각 layer의 feature map에서 나온 결과를 합쳐 NMS알고리즘을 통해 결과를 도출한다.
각 주요과정을 자세히 보면 아래와 같다.
1단계. Feature Extraction (VGG)
pretrained된 VGG를 통해 feature를 추출한다.
2단계. Multi-scale feature maps for detection

추출된 feature map을 다양한 size의 convolution layer에 통과시켜 다양한 resolution의 이미지를 만들고, 만들어진 다양한 resolution의 이미지로 detection한다.
이때 resolution 값이 큰 feature map에서는 하나의 픽셀값이 의미하는 범위가 좁기 때문에 작은 객체를 detection 할 수 있고, resolution 값이 작은 feature map에서는 하나의 픽셀값이 의미하는 범위가 넓기 때문에 큰 객체를 detection 할 수 있다.
3단계. Default boxes and Aspect ratios
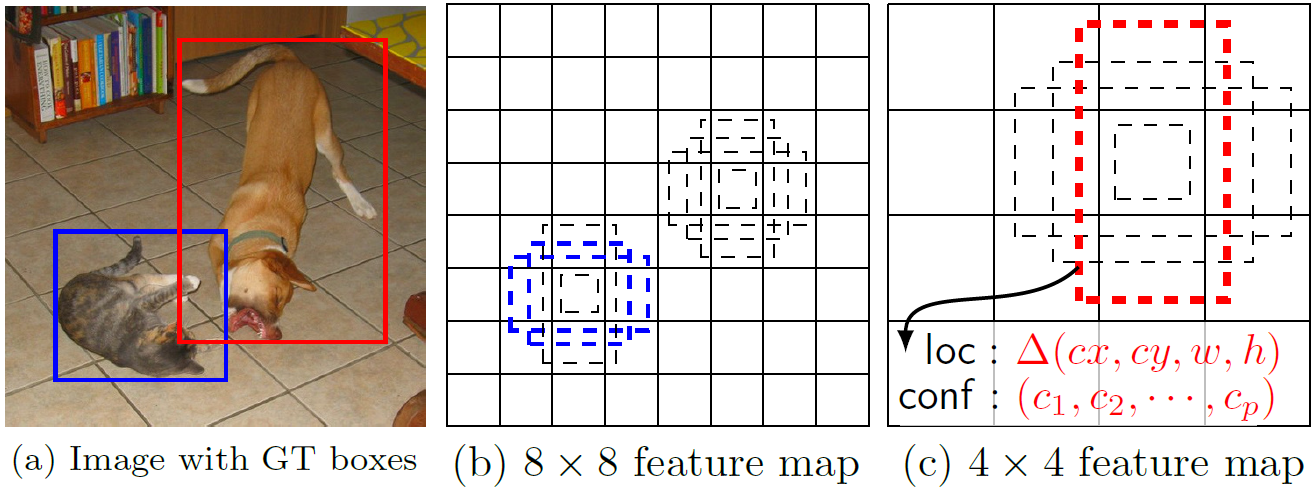
Default box는 Faster R-CNN의 anchor box를 “Multi-scale feature maps for detection”에서 생성되는 여러 scale의 feature map에 맞게 적용시킨 개념이다. 스케일에 상관없이 각 픽셀마다 w, h 값이 aspect ratio로 다르게 생성되어 스케일에 맞는 적절한 default box를 생성한다.

w, h를 구하는 식은 위와 같다. 이때 Smin = 0.2, Smax = 0.9로 지정하였다.
마지막으로 생성된 default box중 ground truth와 IoU가 0.5이상인 box만 남긴다.
4단계. Non-max Suppression (NMS)
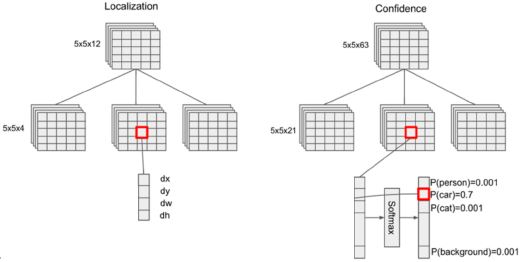
마지막으로 지금까지 생성된 multi-scale feature map과 bbox에 대한 정보를 NMS알고리즘을 사용하여 추려낸다. 자세한 방법은 아래와 같다.
- 먼저 해당 bbox에서 가장 높은 확률을 갖는 label을 고르고, 그 label이 있을 확률에 대해 다른 bbox들을 확률이 높은 순서로 나열한다.
- 그리고 확률값이 제일 큰 bbox와 그 다음으로 큰 bbox의 IoU를 구하여 0.5이상 이면 두 bbox는 많은 부분이 겹친다는 것이기 때문에 공존할 이유가 없어 값을 0으로 바꾸고 IoU가 0.5이하인 것만 남을 때까지 이 과정을 반복한다.
- 다른 label을 기준으로 2번, 3번 과정을 반복하여 bbox를 추려 낸다.
- 최종적으로 정확한 bbox만 남게된다.
Loss Function

전체적인 loss를 살펴 보면 Lconf(classificaion loss)와 Lloc(bounding box의 localization loss)를 합쳐서 구한다. 이때 Lconf은 cross-entropy를 사용했고 Lloc는 smoth L1 loss를 사용했다.
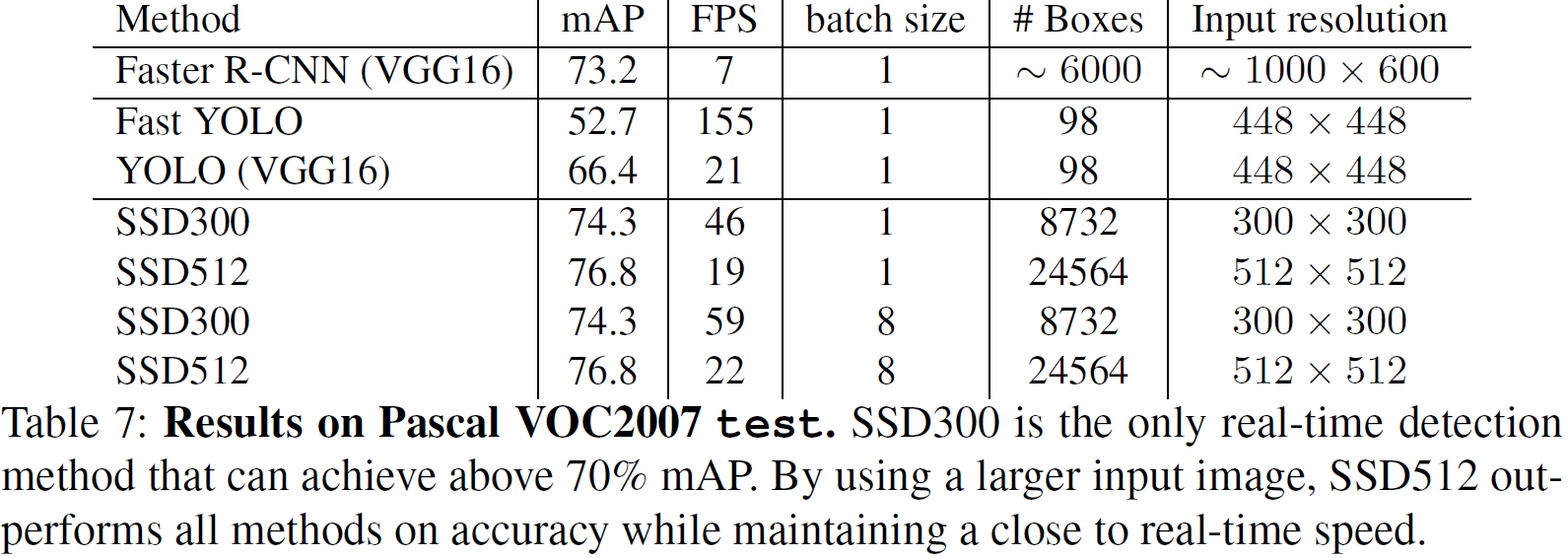
Result
- Results on Pascal VOC2007 test.
- Detection examples on COCO test-dev with SSD512 model.

