[Object Detection] 4. YOLO 논문 리뷰
in Paper-Review
![[Object Detection] 4. YOLO 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/Paper-Review/image/YOLO/img0.png?raw=true)
You Only Look Once: Unified, Real-Time Object Detection (YOLO)
모델 구조

이전의 R-CNN계열의 모델들은 Region proposal과정과 Classification 과정이 나누어져있는 2-Stage Detector 였다. 하지만 YOLO는 그 두가지 과정을 합쳐서 1-Stage Detector의 형태로 Region proposal과정과 Classification 과정이 동시에 이루어 지기 때문에 속도 측면에서 우월한 모습을 보인다.
이 모델은 CNN을 통해 feature extraction하고 얻어낸 정보를 Encoding하여 NMS알고리즘을 통해 detection한다. 자세한 과정은 아래와 같다.
1단계. Feature Extraction (CNN)

YOLO의 detection network는 총 24개의 convolution layer로 이루어져 있다. 먼저 앞쪽 20개 layer는 GoogleNet을 변형시킨 형태인데 이때 feature extraction이 진행된다. 그 뒤에서는 4번의 convolution layer와 2번의 fully connected layer로 7x7x30 사이즈의 정보를 가진 tensor를 output한다.
2단계. Encoding (grids)
- grids

grids방식은 이미지를 격자로 나누어 각각의 칸(grid cell)에 물체가 있는지 여부를 판단하면서 탐색하는 방식이다. 기존의 region proposal 과정에서 사용 되었던 selective search와 edgeboxes는 특징을 이미지 전체에서 sliding window 방식으로 찾았기 때문에 grid cell단위로 검색하는 grids 방식이 속도측면에서 월등히 빠르다.
- encoding

앞서 설명한 feature extraction과정에서 얻은 7x7x30 형태의 output에는 여러가지 정보가 encoding 되있다.
먼저 7x7이 의미 하는 것은 원본 이미지를 grids방식으로 가로 세로 7칸으로 총 49칸으로 나누었다는 것을 의미한다. 즉 7x7에서 한칸이 gridcell을 의미한다.
그리고 하나의 gridcell을 살펴보면 1x1x30의 형태이다. 자세히 살펴보면 앞쪽 5칸에는 해당 gridcell에 있을 수 있는 객체의 bounding box의 정보가 들어있고, 그 다음 5칸에는 다른 bounding box의 정보가 들어있다.
5칸에는 각각 아래와 같은 정보가 들어있다.
- bbox의 중심 x좌표
- bbox의 중심 y좌표
- bbox의 너비
- bbox의 높이
- bbox에 객체가 존재할 확률
그리고 뒷쪽 20칸에는 그 gridcell에 있을 수 있는 여러 label의 존재 확률이 있다.
3단계. Non-max Suppression (NMS)

YOLO에서는 grids 방식으로 각 grid cell에 대해 얻어 낸 정보를 NMS알고리즘을 사용하여 추려내고 정확도를 높인다. 그 방법은 아래와 같다.
- 먼저 각 cell마다 두 개씩 얻은(총 7x7x2 = 98개) 객체의 존재 확률들 중 특정값(threshold)이하인 값을 지운다.
- 그 다음 강아지(label 중 하나 예시)가 있을 확률이 높은 순서로 나열한다.
- 확률값이 제일 큰 bbox와 그 다음으로 큰 bbox의 IoU를 구하여 0.5이상 이면 두 bbox는 많은 부분이 겹친다는 것이기 때문에 공존할 이유가 없어 값을 0으로 바꾸고 IoU가 0.5이하인 것만 남을 때까지 이 과정을 반복한다.
- 다른 label을 기준으로 2번, 3번 과정을 반복하여 bbox를 추려 낸다.
- 최종적으로 정확한 bbox만 남게된다.
Loss Function

이 loss function의 특징적인 부분중 몇가지를 살펴 보면,
- λcoord = 5, λnoobj = 0.5 인데 이는 각각 오브젝트가 있을때와 오브젝트가 없을때를 의미한다. 즉 모델이 오브젝트가 있을때 더 많이 학습하고 없을때는 학습량을 줄이기 위해 loss값을 control한 것으로 파악 할 수 있다.
- 두번째 줄에서 너비와 높이 값에만 루트를 씌운 이유는 객체의 크기에 따라 loss값이 영향 받는 것을 줄이기 위한 것으로 볼 수 있다. 즉 너무 큰 객체과 너무 작은 객체에서 갖는 loss값의 차이를 줄인 것이다.
와 같은 것들이 있고 이 외에도 매우 섬세한 아이디어들이 존재한다.
Result
- PASCAL VOC 2012 Leaderboard.

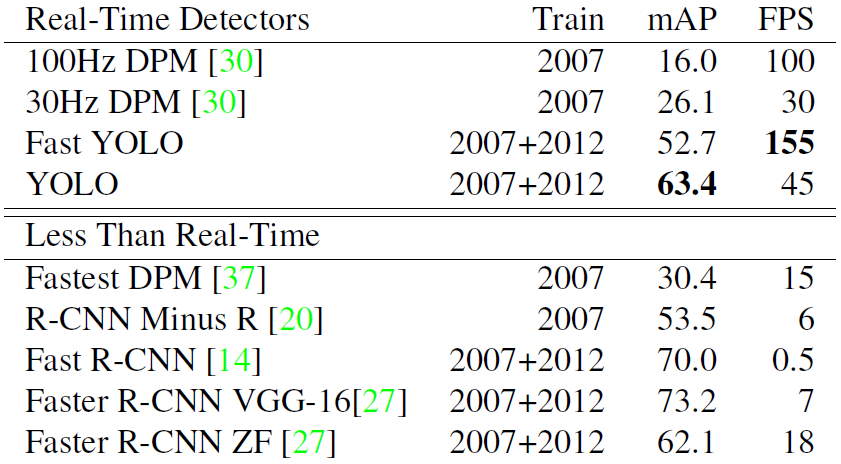
- Real-Time Systems on PASCAL VOC 2007.
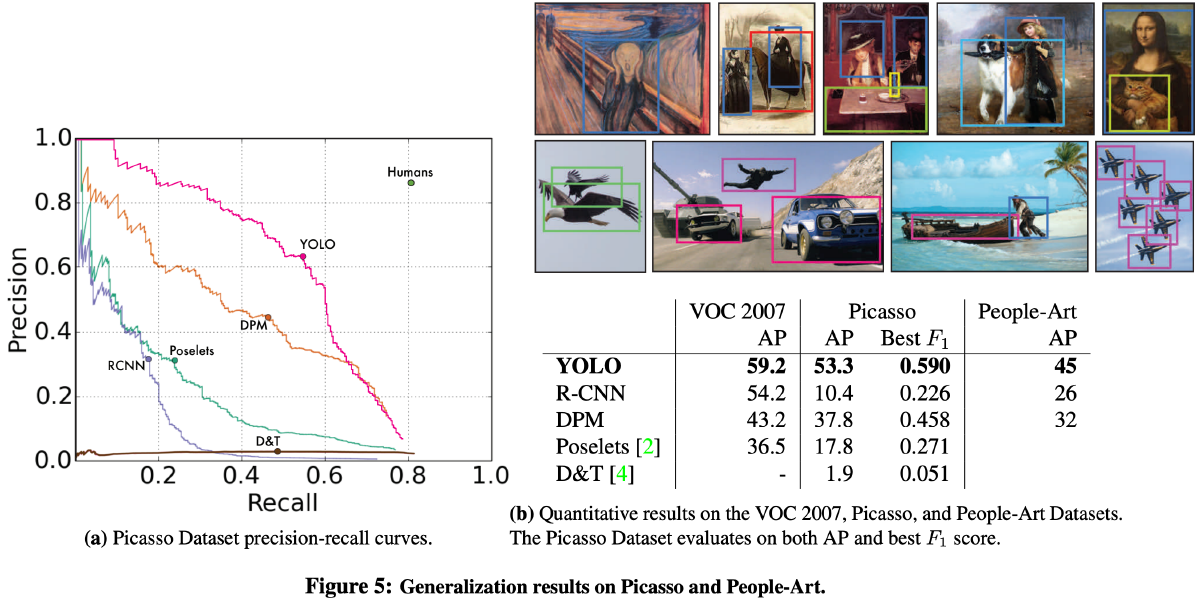
- Generalization results on Picasso and People-Art. - YOLO running on artwork and natural images.