[Object Detection] 1. R-CNN 논문 리뷰
in Paper-Review
![[Object Detection] 1. R-CNN 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/Paper-Review/image/RCNN/img0.jpg?raw=true)
Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)
모델 구조

이 모델은 아래와 같이 크게 3가지 단계로 이루어 진다.
1단계. Region Proposal
먼저 이미지에 대해 후보 영역(region proposal)을 약 2000개정도 생성하고 생성된 후보영역의 이미지를 고정된 크기로 wraping한다.
- Selective Search

selective search는 주변의 색감과 질감의 차이 둘러 쌓여있는지 여부 등을 파악하여 물체의 위치를 파악하는 알고리즘이다. 초반에 생성된 수많은 bounding box들을 merge하여 줄여나가면서 물체의 위치를 조금더 정확하게 파악한다.
- Wraping

selective search로 구한 다양한 크기의 bounding box 들을 뒤에 나올 CNN 모델의 input size에 맞도록 사진을 wraping 한다.
2단계. CNN
모델의 input size에 맞도록 wrapping 된 이미지를 CNN모델에 넣어 이미지의 특징값을 추출(feature extract)한다. CNN 모델은 AlexNet을 변형한 구조이다.
3단계. Classification
- SVM을 사용하여 classification
CNN에서 얻은 feature를 SVM을 통해 분류한다.
- Bounding box regression

앞서 설정된 bounding box의 위치나 크기를 더욱 정확하게 설정하기 위해 위와같은 값으로 regression을 통해 학습한다.
P = 만들어진 bounding box
G = ground truth
x, y = box의 중심좌표
w, h = box의 너비와 높이
기존의 방법과 비교
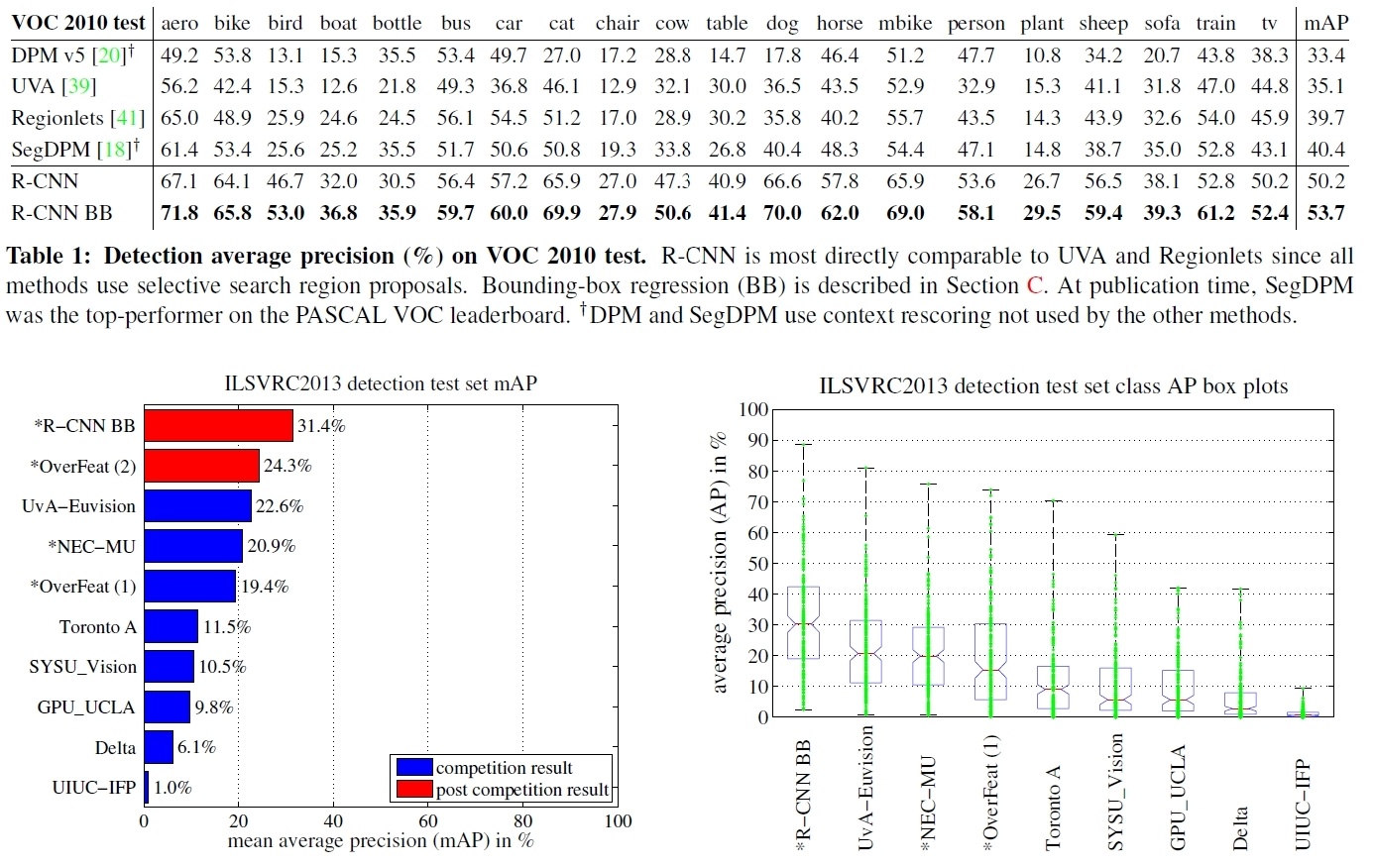
위의 차트와 그래프에서 보면 알 수 있듯이 여러 데이터셋에서 기존의 모델보다 월등한 성능(mAP)을 기록하는 것을 볼 수 있다.
ps. 사실 이 모델은 3가지 단계로 이루어져 있고 처음 selective search에서 생성한 많은 이미지들을 전부 메모리에 할당하고 CNN을 돌려야하기 때문에 굉장히 무겁고 실행속도가 느리다. 따라서 이후에 이러한 단점을 보완한 Fast RCNN, Faster RCNN과 같은 모델이 나오게 된다.
Result
