[Super Resolution] 3-1. SRGAN 논문 리뷰
in Paper-Review
![[Super Resolution] 3-1. SRGAN 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/assets/img/thumbnail/pr-3-1.png?raw=true)
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
모델 구조
그림과 같이 새로운 데이터(SR)을 생성하는 Generator model과 그 데이터를 판단하는 Discriminator model로 이루어졌다. Super-Resolution에서 GAN의 구조를 처음으로 도입하였다.
기존의 방법과 비교

위의 사진은 왼쪽부터 bicubic, MSE를 사용한 모델, SRGAN, 원본이미지이다. 수치상으로 보면 SRResNet이 SRGAN보다 좋지만 눈으로 보기에는 SRGAN이 훨씬 선명한 것을 알 수 있다. 하지만 원본이미지와 비교했을때 머리띠의 문양이나 목부분 장식의 문양이 원본과 완전히 다른 새로운 문양으로 나타났기 때문에 정확도가 중요한 의료파트에서는 쓰기 힘들것으로 보인다.
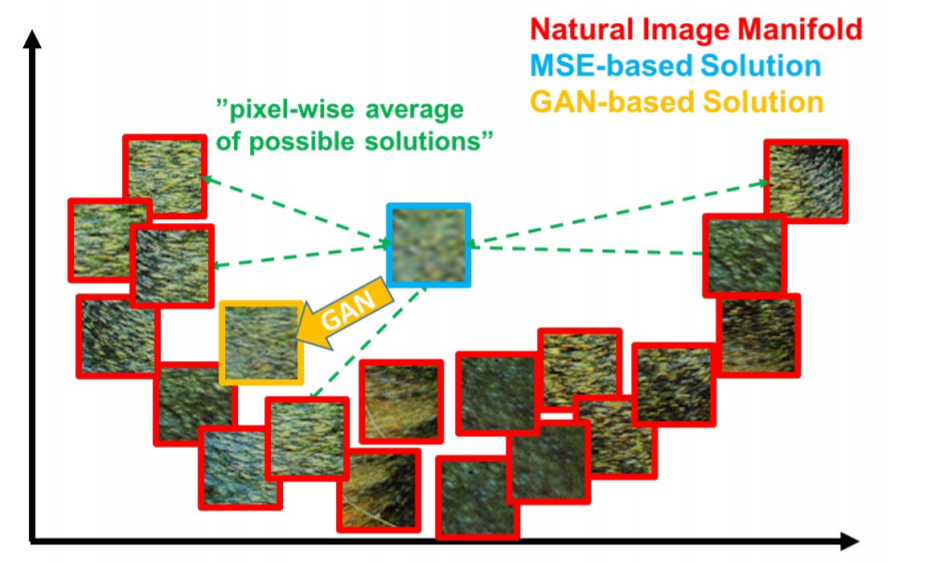
MSE 방식과 GAN 방식을 자세히 비교해보면 먼저 MSE는 가능한 solution 값들의 평균이기 때문에 훨씬 smooth하고 GAN방식은 natural image를 reconstruction 했기때문에 훨씬 convincing하다.
Loss function
- Perceptual loss
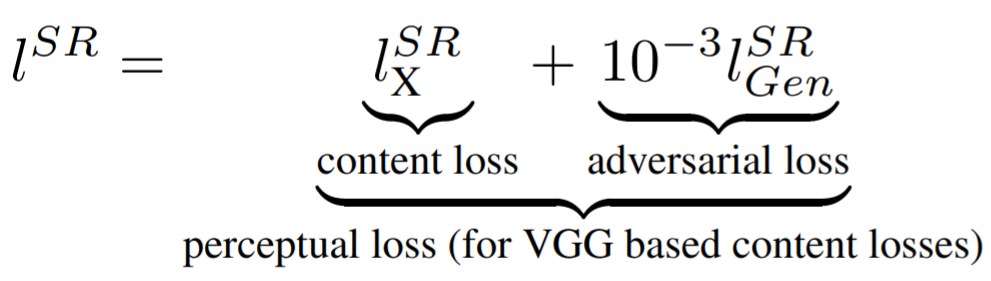
이 논문에서는 두가지 loss를 합쳐 놓은 perceptual loss를 사용하였다.
- Content loss
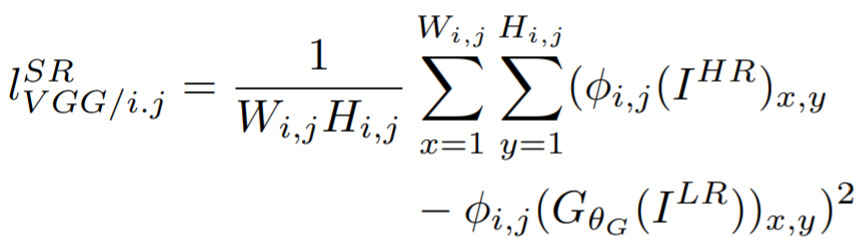
먼저 content loss로 VGG19모델을 사용하여 생성된이미지(SR)과 HR의 VGG모델 내의 feature map의 차이 값을 loss로 사용하였다.
- Adversarial loss
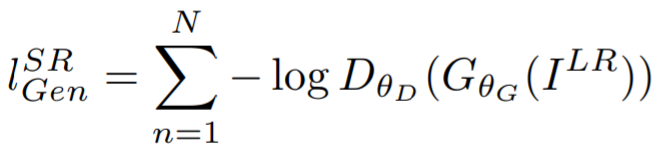
그리고 adversarial loss를 사용하여 생성된 이미지(SR)이 조금 더 진짜 같을 수 있도록 하였다.
이미지 확대 방법
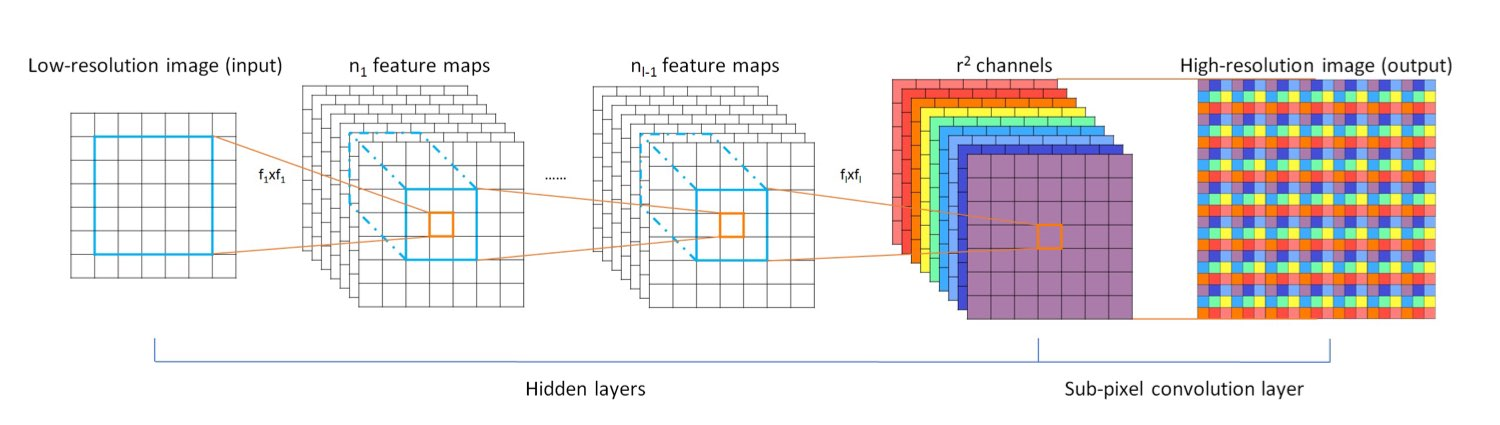
논문에서는 sub-pixel convolution layers라고만 나와있고 그림에는 pixel-shuffler라고만 나와있다. 위의 방법은 Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(ESPCN)에서 소개된 방법으로 기존의 (H x W x C)의 이미지를 r2개의 이미지(H x W x r2C)로 늘리고 이를 그림과 같이 원본보다 r배큰 이미지(rH x rW x C)로 만든다.
Result
