[Super Resolution] 2-2. VDSR 코드 리뷰
in Paper-Review
![[Super Resolution] 2-2. VDSR 코드 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/assets/img/thumbnail/pr-2-2.png?raw=true)
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
모델 구조

그림과 같이 총 20개의 layer로 이루어져있고, 각각 3*3사이즈의 커널로 이루어져 있다. 특이한 점은 19개의 layer를 지나 만들어진 residual(r)값과 skip-connection을 통해 지나온 ILR(x)을 더 하여 고화질의 HR을 출력하는 방식이다. 위의 방법을 통해 기존의 얕은 층 모델에서 깊은 층 모델로 진화할 수 있게 되었다.
Usage
usage: main.py [-h] [--batchSize BATCHSIZE] [--nEpochs NEPOCHS] [--lr LR]
[--step STEP] [--cuda] [--start-epoch START_EPOCH]
[--clip CLIP] [--threads THREADS] [--momentum MOMENTUM]
[--weight-decay WEIGHT_DECAY] [--pretrained PRETRAINED]
[--gpus GPUS] [--optimizer OPTIMIZER]
PyTorch VDSR
optional arguments:
-h, --help show this help message and exit
--batchSize BATCHSIZE
--nEpochs NEPOCHS
--lr LR
--step STEP
--cuda
--start-epoch START_EPOCH
--clip CLIP
--threads THREADS
--momentum MOMENTUM
--weight-decay WEIGHT_DECAY, --wd WEIGHT_DECAY
--pretrained PRETRAINED
--gpus GPUS
--optimizer OPTIMIZER (SGD or Adam)
Data augmentation
flip
for flip in [0,1]:
if flip == 0:
image_f = image
else:
image_f = cv2.flip(image,1)
rotate
def img_rotate(img, degree):
height, width = img.shape
matrix = cv2.getRotationMatrix2D((width/2, height/2), 90*degree, 1)
if degree == 1 or degree == 3:
dst = cv2.warpAffine(img, matrix, (height, width))
else:
dst = cv2.warpAffine(img, matrix, (width, height))
return dst
downsize
def img_downsize(img, ds):
dst = cv2.resize(img, dsize=(0, 0), fx=ds, fy=ds, interpolation=cv2.INTER_LINEAR)
return dst
crop image
def sub_img(input, label, i_size = 33, l_size = 21, stride = 14):
sub_ipt = []
sub_lab = []
pad = abs(i_size-l_size)//2
for h in range(0, input.shape[0] - i_size + 1, stride):
for w in range(0, input.shape[1] - i_size + 1, stride):
sub_i = input[h:h+i_size,w:w+i_size]
sub_l = label[h + pad :h + pad + l_size,w + pad :w + pad + l_size]
sub_i = sub_i.reshape(1, i_size,i_size)
sub_l = sub_l.reshape(1, l_size,l_size)
sub_ipt.append(sub_i)
sub_lab.append(sub_l)
return sub_ipt, sub_lab
down scale
def zoom_img(img, scale):
label = img.astype('float') / 255
temp_input = cv2.resize(label, dsize=(0, 0), fx=1/scale, fy=1/scale, interpolation=cv2.INTER_AREA)
input = cv2.resize(temp_input, dsize=(0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
return input, label
Model
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.conv = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
residual = x
out = self.relu(self.input(x))
out = self.residual_layer(out)
out = self.output(out)
out = torch.add(out,residual)
return out
Train
def train(training_data_loader, optimizer, model, criterion, epoch):
if opt.optimizer == 'SGD':
lr = adjust_learning_rate(optimizer, epoch-1)
for param_group in optimizer.param_groups:
param_group["lr"] = lr
print("Epoch = {}, lr = {}".format(epoch, optimizer.param_groups[0]["lr"]))
model.train()
for iteration, batch in enumerate(training_data_loader, 1):
optimizer.zero_grad()
input, label = Variable(batch[0], requires_grad=False), Variable(batch[1], requires_grad=False)
total_loss = 0
if opt.cuda:
input = input.cuda()
label = label.cuda()
output = model(input)
loss = criterion(output, label)
total_loss += loss.item()
loss.backward()
if opt.optimizer == 'SGD':
nn.utils.clip_grad_norm(model.parameters(),opt.clip)
optimizer.step()
epoch_loss = total_loss/len(training_data_loader)
psnr = PSNR(epoch_loss)
print("===> Epoch[{}]: loss : {:.10f} ,PSNR : {:.10f}".format(epoch, epoch_loss, psnr))
loss function
MSE
criterion = nn.MSELoss(size_average=False)
PSNR
def PSNR(loss):
psnr = 10 * np.log10(1 / (loss + 1e-10))
return psnr
Test
- optimizer를 SGD와 Adam으로 각각 학습시켜 성능을 실험해 본다. 세부 파라미터는 아래와 같다

- Set5를 기준으로 성능을 테스트한 결과는 아래와 같다.

- 논문에 나온 test image로 실험해 보았다.
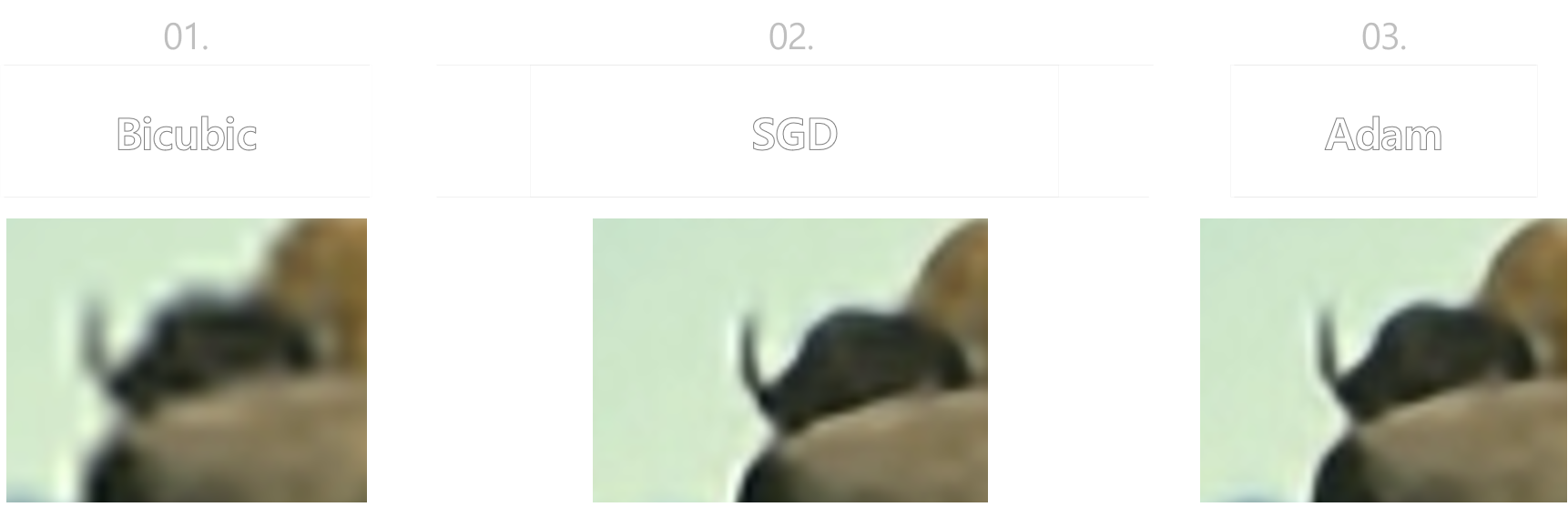
원본 이미지의 뿔부분을 확대하여 보면 눈에 띄게 화질이 좋아진 것을 알 수 있다.