[Super Resolution] 2-1. VDSR 논문 리뷰
in Paper-Review
![[Super Resolution] 2-1. VDSR 논문 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/assets/img/thumbnail/pr-2-1.jpeg?raw=true)
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
모델 구조
그림과 같이 총 20개의 layer로 이루어져있고, 각각 3*3사이즈의 커널로 이루어져 있다. 특이한 점은 19개의 layer를 지나 만들어진 residual(r)값과 skip-connection을 통해 지나온 ILR(x)을 더 하여 고화질의 HR을 출력하는 방식이다. 위의 방법을 통해 기존의 얕은 층 모델에서 깊은 층 모델로 진화할 수 있게 되었다.
기존의 방법과 비교
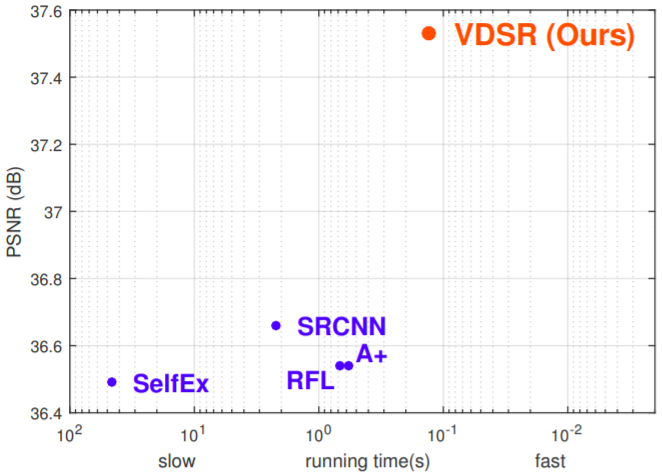
위의 그래프를 통해 확인 할 수 있듯이 PSNR값을 비교해 봤을때 기존의 방법인 SRCNN보다 훨씬 높은 성능을 갖는것을 알 수 있다.
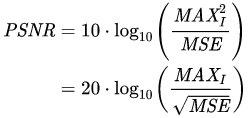
PSNR은 아래와 같은 식으로 구할 수 있으며, 신호가 가질 수 있는 최대 전력에 대한 잡음의 전력이라고 정의되어 있으며 최대값에 대한 노이즈의 값이기 때문에 값이 높을 수록 해상도가 높은 것으로 볼 수 있다.
Loss function

모델의 구조에서 알 수 있듯이 residual image(r)은 r = y - x(y는 HR, x는 LR이다.)로 정의할 수 있고 이때 좋은 모델 이려면 r값이 최소가 되도록 해야한다. 따라서 loss function은 위와 같이 나타낼 수 있다.
실험
- layer 깊이에 따른 각 scale별 성능비교
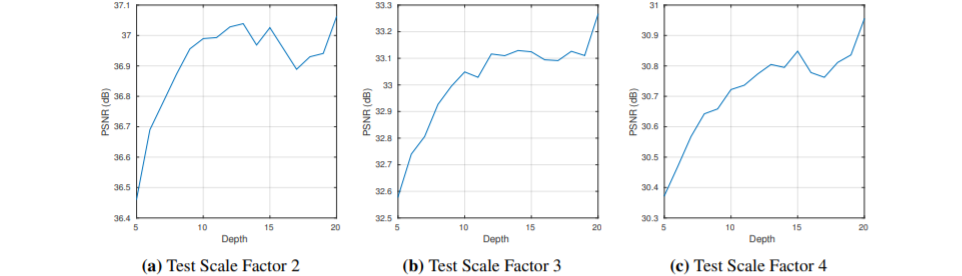
모델의 깊이가 깊을수록 scale factor가 낮을수록 성능이 좋은 것을 알 수 있다.
- 초기 학습률에 따른 residual, non-residual 성능비교
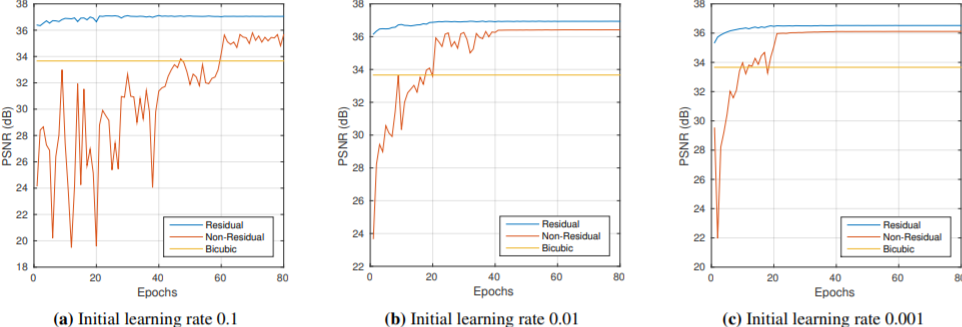
초기 학습률이 작을 수록, non-residual 보다는 residual network가 훨씬 안정적으로 빠르게 수렴하며 성능도 더 높은 것을 알 수 있다.
- 학습시키는 데이터에 따른 성능비교
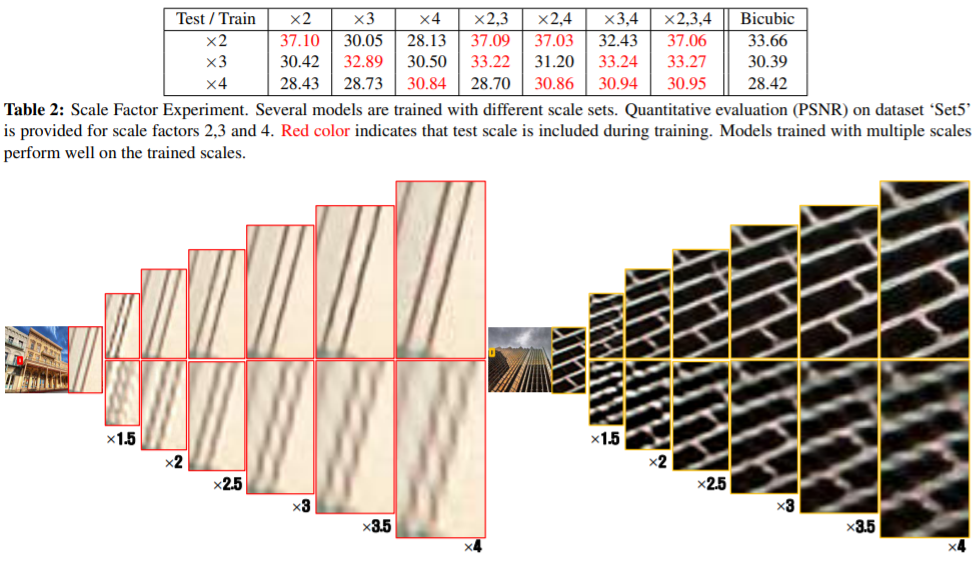
모델을 학습시킬때 여러 scale의 데이터로 학습시킬 수록, 광범위한 scale에서 성능이 높게 나오는 것을 알 수 있다.
Result

