[Super Resolution] 1-2. SRCNN 코드 리뷰
in Paper-Review
![[Super Resolution] 1-2. SRCNN 코드 리뷰](https://github.com/HwangToeMat/HwangToeMat.github.io/blob/master/assets/img/thumbnail/pr-1-2.png?raw=true)
Image Super-Resolution Using Deep Convolutional Networks Code Using Pytorch
모델 구조
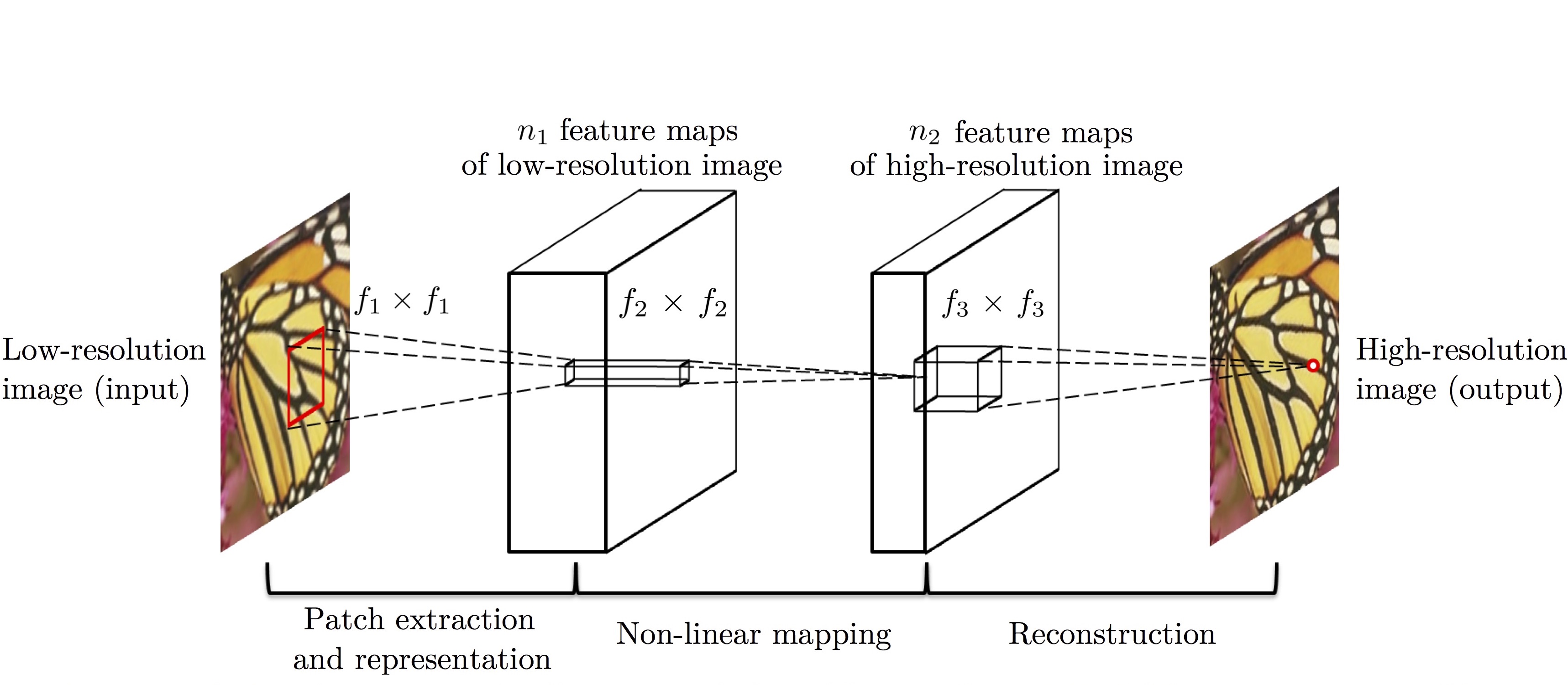
그림과 같이 3개의 layer로 이루어져있고, 각각 9*9, 1*1, 5*5사이즈의 커널로 이루어져 있다. 저해상도의 이미지가 3개의 layer를 지나 고해상도의 이미지를 출력하게 된다.
Usage
usage: main.py [-h] [--batchSize BATCHSIZE] [--nEpochs NEPOCHS] [--lr LR]
[--cuda] [--start-epoch START_EPOCH] [--threads THREADS]
[--pretrained PRETRAINED] [--gpus GPUS]
PyTorch SRCNN
optional arguments:
-h, --help show this help message and exit
--batchSize BATCHSIZE
--nEpochs NEPOCHS
--lr LR
--cuda
--start-epoch START_EPOCH
--threads THREADS
--pretrained PRETRAINED
--gpus GPUS
Data augmentation
rotate
def img_rotate(img, degree):
height, width = img.shape
matrix = cv2.getRotationMatrix2D((width/2, height/2), 90*degree, 1)
if degree == 1 or degree == 3:
dst = cv2.warpAffine(img, matrix, (height, width))
else:
dst = cv2.warpAffine(img, matrix, (width, height))
return dst
crop image
def sub_img(input, label, i_size = 33, l_size = 21, stride = 14):
sub_ipt = []
sub_lab = []
pad = abs(i_size-l_size)//2
for h in range(0, input.shape[0] - i_size + 1, stride):
for w in range(0, input.shape[1] - i_size + 1, stride):
sub_i = input[h:h+i_size,w:w+i_size]
sub_l = label[h + pad :h + pad + l_size,w + pad :w + pad + l_size]
sub_i = sub_i.reshape(1, i_size,i_size)
sub_l = sub_l.reshape(1, l_size,l_size)
sub_ipt.append(sub_i)
sub_lab.append(sub_l)
return sub_ipt, sub_lab
down scale
def zoom_img(img, scale):
label = img.astype('float') / 255
temp_input = cv2.resize(label, dsize=(0, 0), fx=1/scale, fy=1/scale, interpolation=cv2.INTER_AREA)
input = cv2.resize(temp_input, dsize=(0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
return input, label
Model
class Net(nn.Module):
def __init__(self,i_ = 1, c1 = 64, c2=32, c3=1, k1 = 9, k2 = 1, k3 = 5):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(i_, c1, k1)
self.conv2 = nn.Conv2d(c1, c2, k2)
self.conv3 = nn.Conv2d(c2, c3, k3)
torch.nn.init.xavier_uniform_(self.conv1.weight)
torch.nn.init.xavier_uniform_(self.conv2.weight)
torch.nn.init.xavier_uniform_(self.conv3.weight)
torch.nn.init.zeros_(self.conv1.bias)
torch.nn.init.zeros_(self.conv2.bias)
torch.nn.init.zeros_(self.conv3.bias)
def forward(self, x):
x = f.relu(self.conv1(x))
x = f.relu(self.conv2(x))
x = self.conv3(x)
return x
Train
def train(training_data_loader, optimizer, model, criterion, epoch):
print("Epoch = {}, lr = {}".format(epoch, optimizer.param_groups[0]["lr"]))
model.train()
for iteration, batch in enumerate(training_data_loader, 1):
optimizer.zero_grad()
input, label = Variable(batch[0], requires_grad=False), Variable(batch[1], requires_grad=False)
total_loss = 0
if opt.cuda:
input = input.cuda()
label = label.cuda()
output = model(input)
loss = criterion(output, label)
total_loss += loss.item()
loss.backward()
optimizer.step()
epoch_loss = total_loss/len(training_data_loader)
psnr = PSNR(epoch_loss)
print("===> Epoch[{}]: loss : {:.10f} ,PSNR : {:.10f}".format(epoch, epoch_loss, psnr))
loss function
MSE
criterion = nn.MSELoss(size_average=False)
PSNR
def PSNR(loss):
psnr = 10 * np.log10(1 / (loss + 1e-10))
return psnr